Getting Started¶
Molecular Foundation Models are demonstrating impressive performance, but current models use tokenizers that fail to represent all of chemistry; inherently limiting their performance. In particular, Atom-wise tokenizers emit a single token for any bracketed atom, triggering a combinatorial exposition of the vocabulary size. Capturing all variants of Carbon atoms would require 75,600 tokens, or nearly a quarter of the GPT-4o’s vocabulary (Wadell et al.).
The problem is that most atoms are bracketed. Any element outside the organic subset, chiral centers, isotopes, or charged species are all encoded as bracketed atoms. Bracketed atoms encode the nuclear, electronic, and geometric features that are critical to numerous widely-used compounds, including:
Cisplatin: An effective chemotherapy drug on the World’s Health Organizations List of Essential Medicines. However, its isomer Transplatin is not an effective drug.
Sodium pertechnetate: A radiopharmaceutical used for thyroid imaging.
Lithium Iron Phosphate: A widely used cathode material for batteries powering everything from consumer electronics to electric vehicles.
Smirk fixes this by tokenizing SMILES encodings all the way down to their constituent elements. Enabling the complete coverage of OpenSMILES with a vocabulary of 167 tokens.
Check out the paper for all the details; otherwise, let’s see it in action!
🐍 Installation is easy with pre-build binaries on PyPI and GitHub. Just run: pip install smirk
Installing from source? See installing from source for instructions.
!python -m pip install smirk transformers rdkit
First steps¶
🤗 smirk subclasses Hugging Face’s PreTrainedTokenizerBase for seamless compatibility and leverages Tokenizers for raw rust-powered speed. No need to learn another framework; everything works out of the box 🎁
from smirk import SmirkTokenizerFast
# Just import and tokenize!
smirk = SmirkTokenizerFast()
smirk("CC(=O)Nc1ccc(O)cc1")
{'input_ids': [45, 45, 4, 22, 102, 5, 93, 153, 12, 153, 153, 153, 4, 102, 5, 153, 153, 12], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
# Batch Tokenization with Padding
batch = smirk([
"C[C@@H]1CCCCCCCCCCCCC(=O)C1",
"O=C(O)C[C@H](N)C(=O)N[C@H](C(=O)OC)Cc1ccccc1",
"CN(C)S[N][Re@OH18]([C][O])([C][O])([C][O])([C][O])[C][O]"
], padding="longest")
batch
{'input_ids': [[45, 148, 45, 24, 71, 150, 12, 45, 45, 45, 45, 45, 45, 45, 45, 45, 45, 45, 45, 45, 4, 22, 102, 5, 45, 12, 162, 162, 162, 162, 162, 162, 162, 162, 162, 162, 162, 162, 162, 162, 162, 162, 162, 162, 162, 162, 162, 162, 162, 162, 162, 162, 162], [102, 22, 45, 4, 102, 5, 45, 148, 45, 23, 71, 150, 4, 93, 5, 45, 4, 22, 102, 5, 93, 148, 45, 23, 71, 150, 4, 45, 4, 22, 102, 5, 102, 45, 5, 45, 153, 12, 153, 153, 153, 153, 153, 12, 162, 162, 162, 162, 162, 162, 162, 162, 162], [45, 93, 4, 45, 5, 122, 148, 93, 150, 148, 116, 26, 12, 19, 150, 4, 148, 45, 150, 148, 102, 150, 5, 4, 148, 45, 150, 148, 102, 150, 5, 4, 148, 45, 150, 148, 102, 150, 5, 4, 148, 45, 150, 148, 102, 150, 5, 148, 45, 150, 148, 102, 150]], 'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]}
# Back to molecules!
smirk.batch_decode(batch["input_ids"], skip_special_tokens=True)
['C[C@@H]1CCCCCCCCCCCCC(=O)C1',
'O=C(O)C[C@H](N)C(=O)N[C@H](C(=O)OC)Cc1ccccc1',
'CN(C)S[N][Re@OH18]([C][O])([C][O])([C][O])([C][O])[C][O]']
# By default, we don't add `[CLS]` and `[SEP]` tokens, but that's just a flag
smirk_bert = SmirkTokenizerFast(template="[CLS] $0 [SEP]")
" ".join(smirk_bert.tokenize("CNCCC(c1ccccc1)Oc2ccc(cc2)C(F)(F)F", add_special_tokens=True))
'[CLS] C N C C C ( c 1 c c c c c 1 ) O c 2 c c c ( c c 2 ) C ( F ) ( F ) F [SEP]'
What Makes Smirk Special?¶
By fully decomposing the input molecule, smirk ensures complete coverage of the OpenSMILES specification. Any valid OpenSMILES encoding can be tokenized by smirk without emitting unknown tokens. Moreover, for non-bracketed atoms, the smirk tokenization is the same as an Atomwise tokenizer used by current molecular foundation models such as MoLFormer.
A new version of the following files was downloaded from https://huggingface.co/ibm/MoLFormer-XL-both-10pct:
- tokenization_molformer.py
. Make sure to double-check they do not contain any added malicious code. To avoid downloading new versions of the code file, you can pin a revision.
A new version of the following files was downloaded from https://huggingface.co/ibm/MoLFormer-XL-both-10pct:
- tokenization_molformer_fast.py
- tokenization_molformer.py
. Make sure to double-check they do not contain any added malicious code. To avoid downloading new versions of the code file, you can pin a revision.
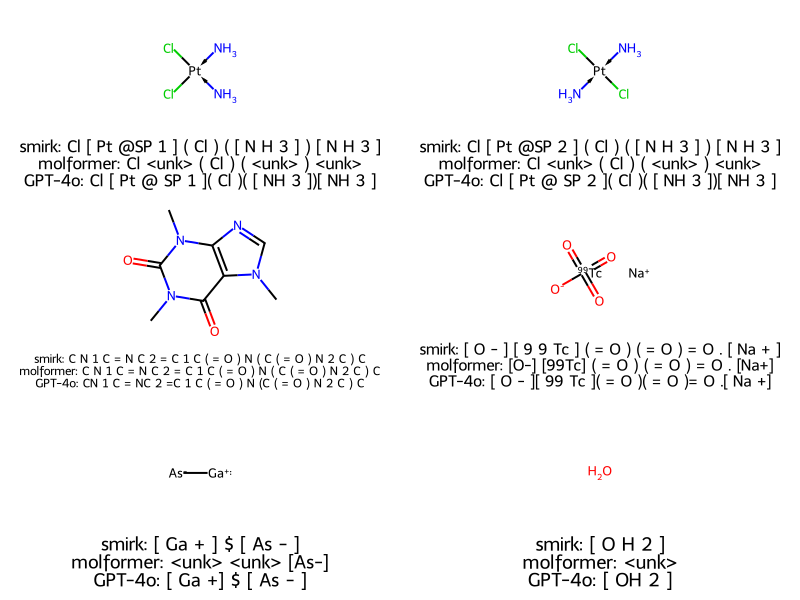
Smirk tokenized all molecules without a single unknown, whereas MoLFormer’s Atomwise tokenizer emitted the unknown token for both Cisplatin and Transplatin (First row). Conversely, the Atomwise tokenizer emitted unknown tokens for the following:
Platinum chiral centers:
[Pt@SP1]and[Pt@SP2]Ammonia & Water with explicit hydrogens:
[NH3]and[OH2]Gallium ion:
[Ga+]Quadbond:
$
As a data-driven method, Atomwise tokenizers only know about the atoms seen during their training; fundamentally limiting their generalization ability.
Zero to Molecular Foundation Model with Smirk!¶
Let’s train a small RoBERTa model on molecules from QM9 using Hugging Face and smirk.
!python -m pip install accelerate datasets torch
Dataset Preprocessing¶
from datasets import load_dataset
# MoleculeNet's QM9 dataset. Normally this would be a larger (and unlabeled)
# dataset. But for a demo, it's perfect
dataset = load_dataset("csv",
data_files=["https://deepchemdata.s3-us-west-1.amazonaws.com/datasets/qm9.csv"],
)["train"].select_columns("smiles").train_test_split(test_size=0.2)
# Tokenizer the splits! For a larger dataset, this would be done on-the-fly
dataset = dataset.map(smirk, input_columns=["smiles"], desc="Tokenizing")
💡 huggingface/tokenizers may raise a warning about being forked as we’ve already used our tokenizers (this isn’t a smirk issue). It’s harmless, but when actually training it’s best to avoid tokenization until after the fork to benefit from the rust-level parallelism
🎉 That’s it! We’ve tokenized all of QM9 using smirk!
dataset["train"].to_pandas().head()
| smiles | input_ids | attention_mask | |
|---|---|---|---|
| 0 | CC12C3C4N1C2C34C#C | [45, 45, 12, 13, 45, 14, 45, 15, 93, 12, 45, 1... | [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, ... |
| 1 | OCCCC1CC(=O)O1 | [102, 45, 45, 45, 45, 12, 45, 45, 4, 22, 102, ... | [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1] |
| 2 | CCNc1nc([nH]n1)O | [45, 45, 93, 153, 12, 154, 153, 4, 148, 154, 7... | [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1] |
| 3 | O=C1NC23CN(C2)CC13 | [102, 22, 45, 12, 93, 45, 13, 14, 45, 93, 4, 4... | [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, ... |
| 4 | CC1(C)C(O)C11CCO1 | [45, 45, 12, 4, 45, 5, 45, 4, 102, 5, 45, 12, ... | [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, ... |
Training¶
Once we’ve tokenized the dataset, training the model is just a matter of configuration.
from accelerate import Accelerator
from transformers import Trainer, TrainingArguments, RobertaForMaskedLM, RobertaConfig, DataCollatorForLanguageModeling
# A very small model for demonstrating training a molecular foundation model with smirk
config = RobertaConfig(
vocab_size=len(smirk),
hidden_size=256,
intermediate_size=1024,
num_hidden_layers=4,
num_attention_heads=4,
)
model = RobertaForMaskedLM(config)
# Setup up the trainer to use our dataset
trainer = Trainer(
model=model,
train_dataset=dataset["train"],
eval_dataset=dataset["test"],
processing_class=smirk,
data_collator=DataCollatorForLanguageModeling(smirk), # The data collator needs to know about our tokenizer
)
trainer.train()